What Is A Database?
I defined information architecture as a discipline that emphasizes organizing and presenting information in a way that ensures optimum findability and usability across different media devices and channels. A database is one tool that information architects use to assist them in disseminating information in the most effective way possible.
A database is a type of organization structure; in relation to a website, the organization structure more often than not serves as the primary navigation system. When a user browses a website by clicking or hovering over the top navigation—About, Academics and News categories on a university website for instance—he is interacting with that website’s database. And databases organize everything from web pages, web page schemas or types; and the content on those pages, from photos, to text, to linked document files.
Databases are meant to help information architects battle the problem of decentralization. With the rise of the Internet age, one can get information from a myriad of digital sources, and architects need to keep pushing the envelope when it comes to organization practices just to stay moderately effective: “As the Internet provides users with the freedom to publish information, it quietly burdens them with the responsibility to organize that information. New information technologies open the floodgates for exponential content growth, which creates a need for innovation in content organization.”
From the larger umbrella of decentralization, there are challenges that information architects must tackle head-on when designing databases.
One of the main problems information architects must wrestle with is ambiguity. According to Information Architecture: For the Web and Beyond, “Classification systems are made of language, and language is ambiguous: words are capable of being understood in more than one way.” This is why it’s imperative that information architects take into account the audience when designing databases, especially when it comes to labeling information and adopting organization schemes. If your target audience is the age 18-30 demographic, the terminology you might employ for categories and labels should appeal to that demographic. However, there will be a little give-and-take at play here—you can optimize your database for that younger demographic, but a secondary or tertiary audience consisting of 55-75 year-olds might have trouble accessing the information they’re looking for simply because they might not be as familiar with a youthful vocabulary. (Sidenote: My mom used the term “on fleek” on a recent road trip and I just about pumped the brakes and went flying through the windshield. Don’t do that again, mom.) Classifying bits of information within these labels and categories also adds to the complexity of the problem.
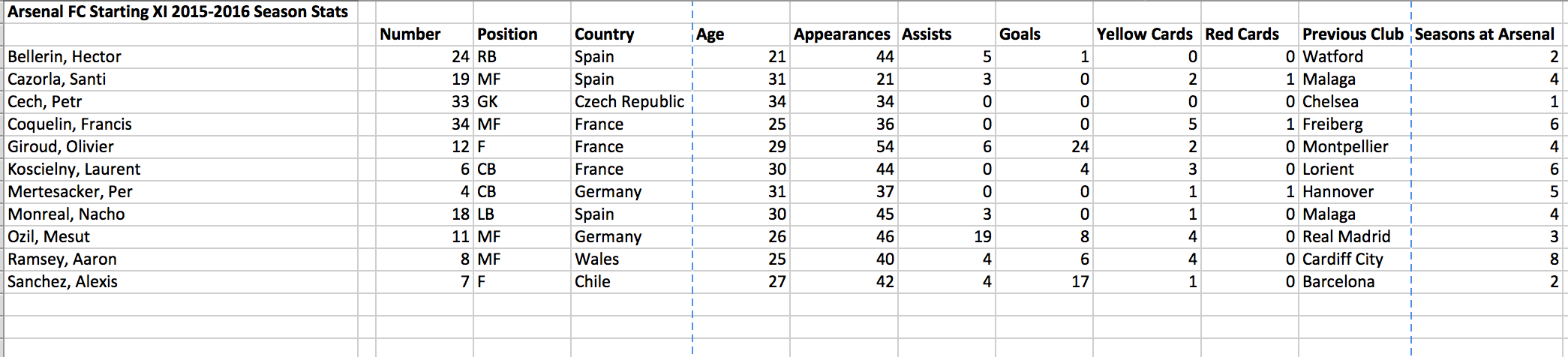
An example of a flat database using Arsenal FC player statistics and categories.
In keeping with the librarian/library theme of module one, information architects also have to deal with heterogeneous information. The card catalog is a relatively simple library database that deals with homogeneous information: “Each book has a record in the catalog. Each record contains the same fields: author, title, and subject. It is a high-level, single-medium system, and it works fairly well.” However, information architects have to deal with different content types such as photography, text, video, and other forms of media. As a web writer and editor, I might have to create a webpage that pulls in a video file, a couple of .jpg photo files, link to a .PDF on our server, and compile all of the text within the content management system. In short, I have to think about a lot of different types of content, and our database helps me do my job effectively.
Information architects also have to take perspective into consideration when creating a database: “How does a customer visiting this website know where to go for technical information about a product she just purchased? To design usable organization systems, we need to escape from our own mental models of content labeling and organization.” Perspective ties into ambiguity in that both challenges deal with audiences. My team is in the middle of a complete redesign of the Quinnipiac.edu website, and we’re aiming to make the experience more user-centric instead of institute-centric. Most university websites have a global navigation organized by the traditional structure of About, Academics, Admissions, Student Life, Athletics, News, Research, Parents and Alumni. This is all well and good if the aim of the website is to organize content by office or category, but this setup isn’t necessarily directed at the 16- or 17-year-old looking to find out what separates Quinnipiac University from the rest of the schools in the nation.
To help us out, our team created personas of prospective undergraduate and prospective graduate students. This allowed us to get out of our own university-centric perspective and into the perspectives of our audience—rather than have an overwhelming dropdown navigation, we split up the navigation into a burger menu and a schools jumper that directs a prospective student to where he or she needs to go in fewer clicks.
Metadata is one of the main benefits of adopting a database-driven organization structure. Tagging heterogeneous pieces of information and content with metadata allows for more effective search capabilities and linking. Without metadata, the goal of creating a user-centric web experience is practically impossible.
Resources:
Rosenfeld, Louis, Peter Morville, and Jorge Arango. Information Architecture For the Web and Beyond. Sebastopol, CA: O’Reilly Media, Inc., 2015. Print.